Gebruikersonderzoek CABR (2)

Blog 2
Klaar voor de start: leer je gebruikers en hun wensen kennen
Wat hebben mensen nodig om met een digitaal archief te werken? Snappen ze de interface van de website? Gebruikersonderzoek kan deze vragen beantwoorden. In vier blogs vertelt Lotte Baltussen van het Huygens Instituut over het gebruikersonderzoek dat zij uitvoerde voor het project Oorlog voor de Rechter. Hierin wordt het CABR (Centraal Archief Bijzondere Rechtspleging), het grootste oorlogsarchief van Nederland, digitaal toegankelijk gemaakt.
Deze blogserie geeft handvatten voor het zelf (laten) uitvoeren van gebruikersonderzoek in voor, tijdens en rond de lancering een digitaal project met praktische voorbeelden.
Wat is de centrale vraag?
Het doel van het project Oorlog voor de Rechter is het breed en digitaal toegankelijk maken van het Centraal Archief Bijzondere Rechtspleging (CABR). Dit is het grootste en meest geraadpleegde Tweede Wereldoorlogsarchief van Nederland en bevat dossiers van 425.000 personen die onderzocht zijn op mogelijke collaboratie met de Duitse bezetter.
De centrale vraag: hoe maak je een groot en complex archief als het CABR laagdrempelig toegankelijk voor gebruikers? Dat begint met het in kaart brengen van de (beoogde) gebruikers en hun wensen, al in de voorbereidingsfase van je project.
Interviews voor opstellen gebruiksprofielen
We begonnen in de zomer van 2023 met het maken van gebruiksprofielen om focus aan te brengen. Er waren eerder veel soorten mogelijke gebruikers gedefinieerd: van nabestaanden van onderzochte personen en slachtoffers tot journalisten, wetenschappers en scholieren. Maar: als je een website maakt voor iedereen, maak je hem voor niemand.
Om inzicht te krijgen in de verwachte (hoofd)gebruikers van het digitale CABR en hun belangrijkste doelen, pijnpunten en wensen, hielden we interviews met alle gebruikersgroepen.

Overzicht van de deelnemers aan de eerste ronde interviews. Iconen van de Noun Project (family van Astonish, archivist van Miroslav KURDOV, education van Fatemah Manji, journalist, museum van gilang putra arkian; rechten CC BY 3.0).
Aanpak van de interviews
De interviews duurden ongeveer een uur en vonden fysiek plaats in Amsterdam of Den Haag, of hybride via Teams. We stelden van tevoren de doelstellingen van het onderzoek op en de gewenste diversiteit van deelnemers. Het bleek eenvoudig om deelnemers te vinden in de Randstad, maar we wilden liever een brede geografische spreiding dus gingen we op zoek in het hele land.
We maakten een interviewscript en stelden iedere deelnemer dezelfde vragen. Dit deden we semi-gestructureerd, zodat het interview voelde als een natuurlijk gesprek. Vragen die in de loop van het gesprek waren overgeslagen, stelden we alsnog bij het afsluiten van het gesprek als dit organisch paste. Een moderator voerde het gesprek, een observator maakte aantekeningen en vulde waar nodig de moderator aan.
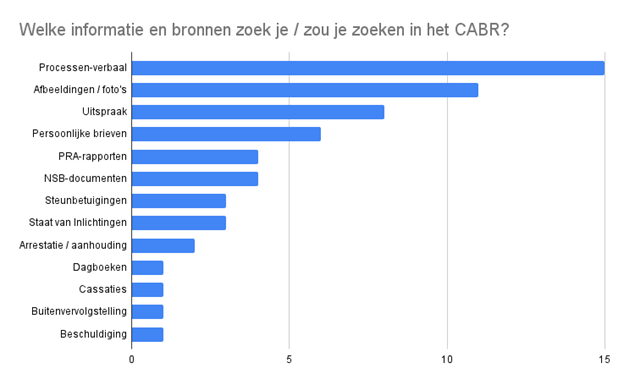
Belangrijke documenttypes volgens de deelnemers aan de eerste interviews.
Van gebruikerswensen naar technologie
Een belangrijk leerpunt van de interviews was dat mensen meer grip wilden krijgen op het CABR. Er zitten talloze documenttypes in het archief die niet zijn geclusterd op datum of soort. Uit de interviews kwam de wens aan clustering sterk naar voren. Deelnemers begonnen hun zoektocht vaak bij processen-verbaal met verhoren van verdachten en getuigen en bij uitspraken (‘Ik wilde meteen weten hoe erg het was wat opa heeft gedaan’).
Dit zorgde dat automatische documentclassificatie een groot focuspunt werd in het project. Hierdoor kunnen gebruikers van het digitale CABR nu belangrijke juridische documenten zien in de context van de rechtsgang: van aangifteformulieren bij het begin van het onderzoek tot een uitspraak van de rechter aan het einde.
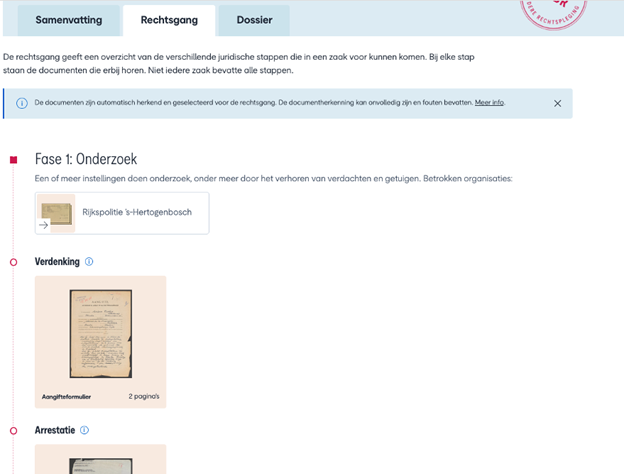
De rechtsgang in het digitale CABR: resultaat van interviews en later onderzoek.
Snel testen op basis van digitale schetsen
Een ander belangrijk aandachtspunt uit de interviews was terminologie. Niet iedereen weet wat het Nationalsozialistisches Kraftfahrkorps was, of het verschil tussen een Tribunaal en een Bijzonder Gerechtshof. Belangrijke context die nodig is om informatie goed te interpreteren.
We wilden daarom uitleg te geven bij termen in scans. Iedere term beschrijven kost te veel tijd en sommige termen zijn duidelijk genoeg. Maar welke beschrijf je dan wel? En hoeveel detailniveau is er nodig, zonder dat je teksten te lang worden?
Met die vragen in het achterhoofd maakten we op basis van een paar scans, zonder privacygevoelige informatie, digitale schetsen (mock-ups) van hoe dit eruit kan zien.
Niet te veel details, wel voorbeelden
We voerden de tests eind 2023 online uit door de schetsen in Teams via schermdelen te tonen. Eerst lieten we scans zien zonder termen uit te lichten en vroegen we deelnemers over welke termen ze meer over wilden weten. Daarna lieten we uitleg zien, met meer en minder detailniveau.

Mock-up die is gebruikt voor de test met de uitleg van termen tonen. In deze mock-up staat de uitleg nog in de tekstherkenning, niet in de scan.
We testten met 5 personen en dat bleek voor deze ronde genoeg. Er was veel overeenstemming. Zo was de standaardlengte van 3-5 zinnen die we hadden gekozen goed: ‘veel langer moet het niet worden’. Een reden om wel wat langere beschrijvingen te maken is wanneer voorbeelden helpen een term te verduidelijken. Maar details die weinig te maken hadden met de kern moesten we weglaten.
Verder kregen we input voor het aanvullen van onze termenlijst met veelvoorkomende begrippen als ‘Goed Nederlanderschap’ en ‘Proeftijd’. We waren zo gefocust op organisaties en onbekende juridische termen, dat dit soort termen niet op ons netvlies stonden terwijl die toch een toelichting nodig hadden.

Uiteindelijke presentatie van de uitleg van termen. Niet in de tekstherkenning zoals in de mock-up, maar als venster in het document. De term heeft een iets andere beschrijving gekregen, zonder onnodige details.
Sneltest op papier: transcripties tonen
In april 2024 testten we opties voor het tonen van tekstherkenning van documenten. Hiervoor hadden we weinig tijd dus we kozen ervoor om de ontworpen opties uit te printen. Met de schetsen in de hand bevroegen we een tiental collega’s over hun voorkeuren voor opties, zoals tekst over de scan leggen of naast de test tonen.
Hieruit bleek dat het over de scan plaatsen van de herkende tekst de authenticiteit van de bron te veel zou aantasten. Deze optie had in eerste instantie bij sommige stakeholders binnen het project de voorkeur. Zou de optie zijn doorgevoerd zonder onderzoek, dan had dit veel gebruikers teleurgesteld en mogelijk zelfs het vertrouwen in het project geschaad.
Achteraf aanpassen had dan ook weer veel doorloop- en ontwikkeltijd gekost, veel meer dan de 4 uurtjes die het nu tijdens het gebruikersonderzoek kostte om de papieren opties uit te printen en rond te laten gaan.
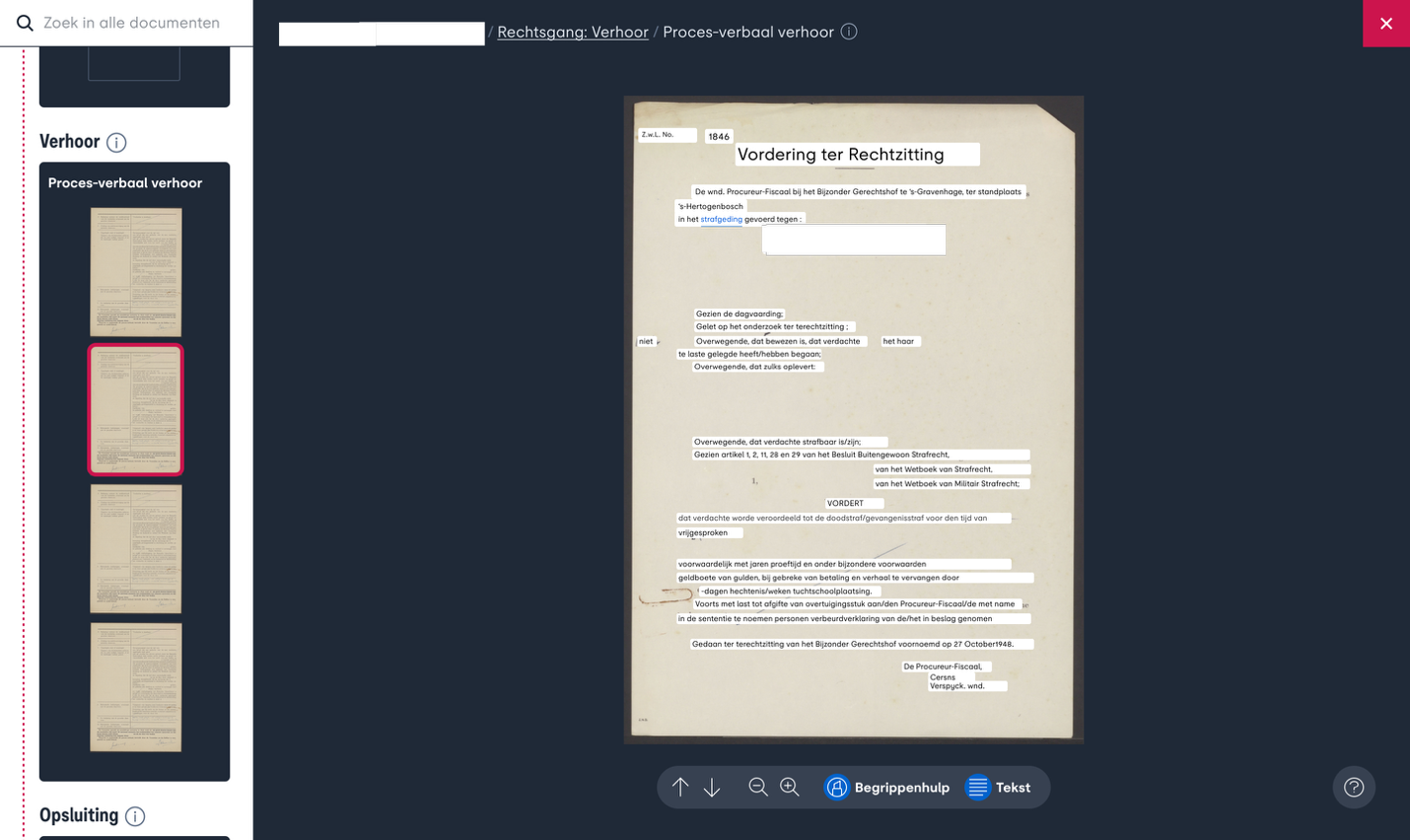
Ontwerp met tekstherkenning op de scan.
Lessen uit de voorbereiding
Tijdens de voorbereidingsfase was er nog niets technisch ontwikkeld waar deelnemers aan het onderzoek op konden reageren. Gelukkig maar, want uit de interviews en tests met een mock-up en een papieren prototype bleek dat de voorkeur die er was bij sommigen (tekst over scan plaatsen) niet gewenst was. Dit was kostbaar geweest om aan te passen!
Na deze goede voorbereiding waren we klaar voor de ontwikkelfase. Hierin maakten we de gebruikerswensen uit de onderzoeken van de voorbereiding concreet en testten we het volledige concept van de website. Lees er meer over in de volgende blog post!

Terug naar Gebruikersonderzoek meenemen voor de start van een digitaal project

Door naar Voorkomen is beter dan repareren: neem de hordes voordat je bouwt